|
|
|
|
|
|
|
|
|
|
|
code |
paper |
cite |
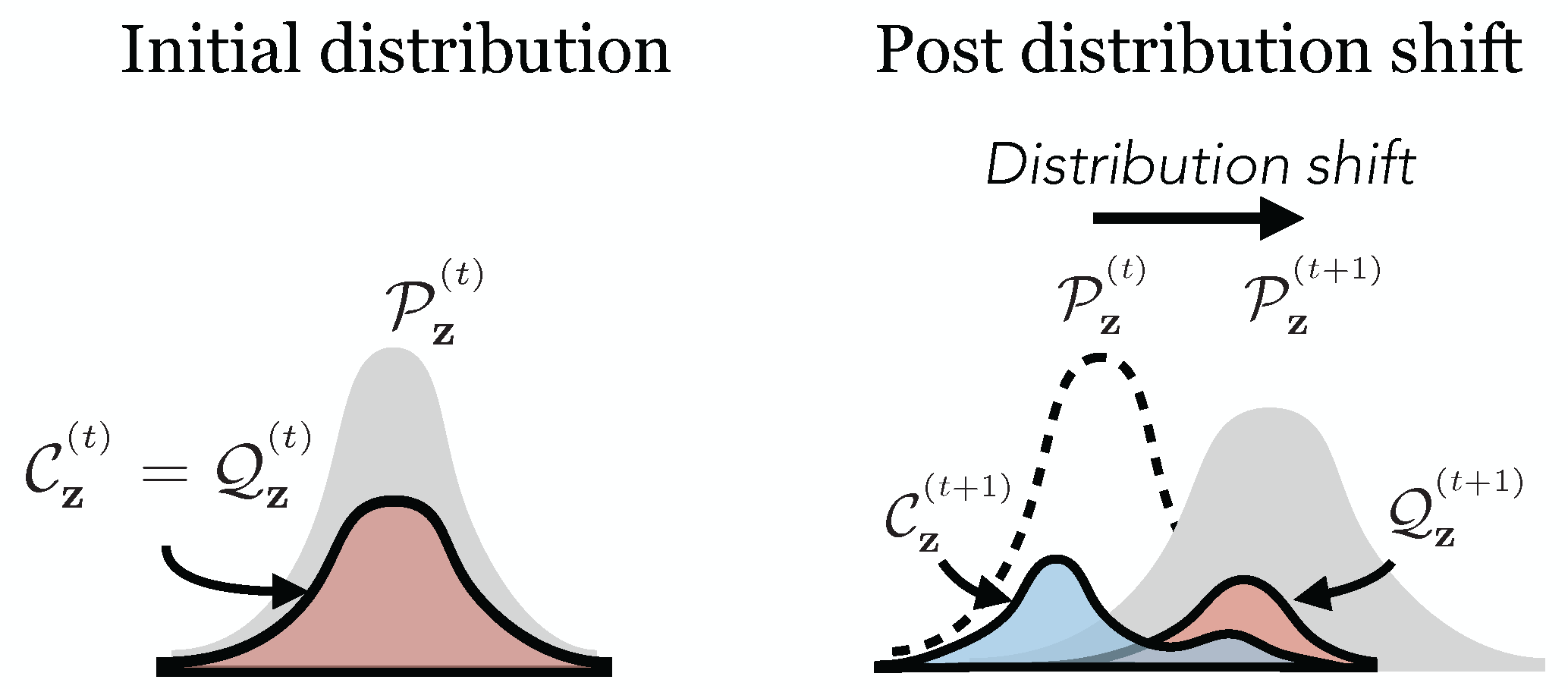
We observe that a primary cause of training instability is attributed to a shift in the embedding distribution. As the embedding distribution P shifts, it misaligns with the codebook distribution C. The misalignment occurs due to the sparse, delayed, and inaccurate straight-through estimation used to update the codebook. The set of assigned code-vectors Q continuously shrinks as models are trained for longer. This phenomenon is referred to as "index collapse".
To reduce this divergence, we propose an affine re-parameterization of the code-vectors that can better match the moments of the embedding representation. An affine re-parameterization with shared parameters ensures that the code-vectors that do not have an assignment still receive gradients. The affine parameters can either be learned or computed using running statistics. This can be easily extended beyond a single affine parameter to a group.

We can directly observe the effect of affine re-parameterization by visualizing the P, C, and Q using a low-dimensional projection.
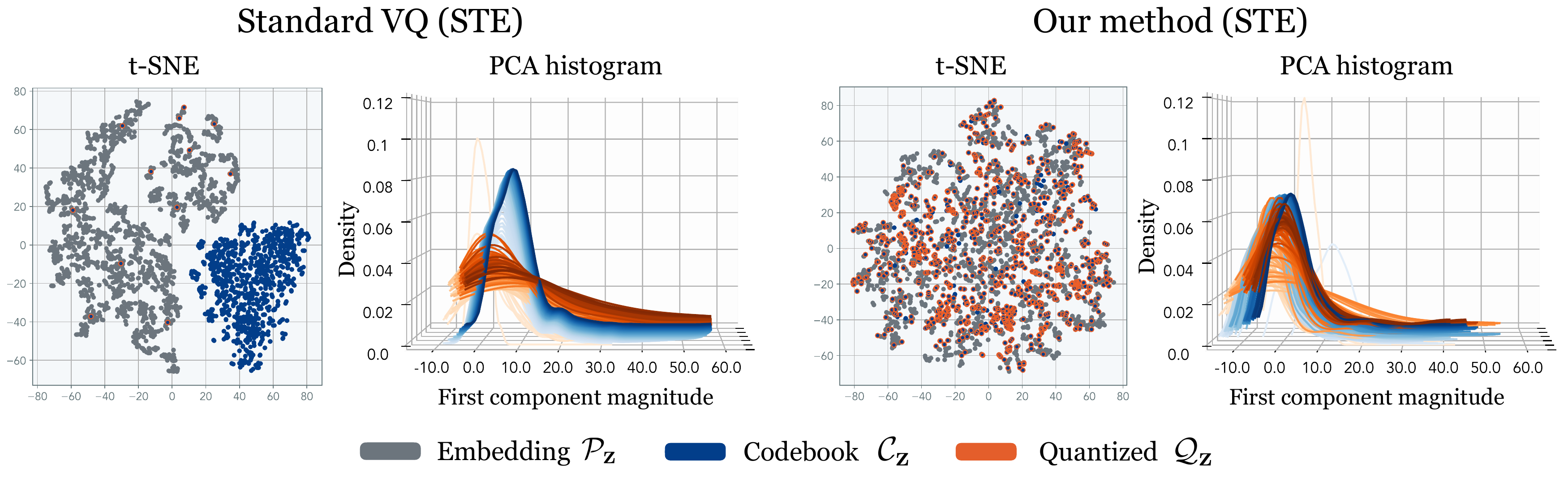
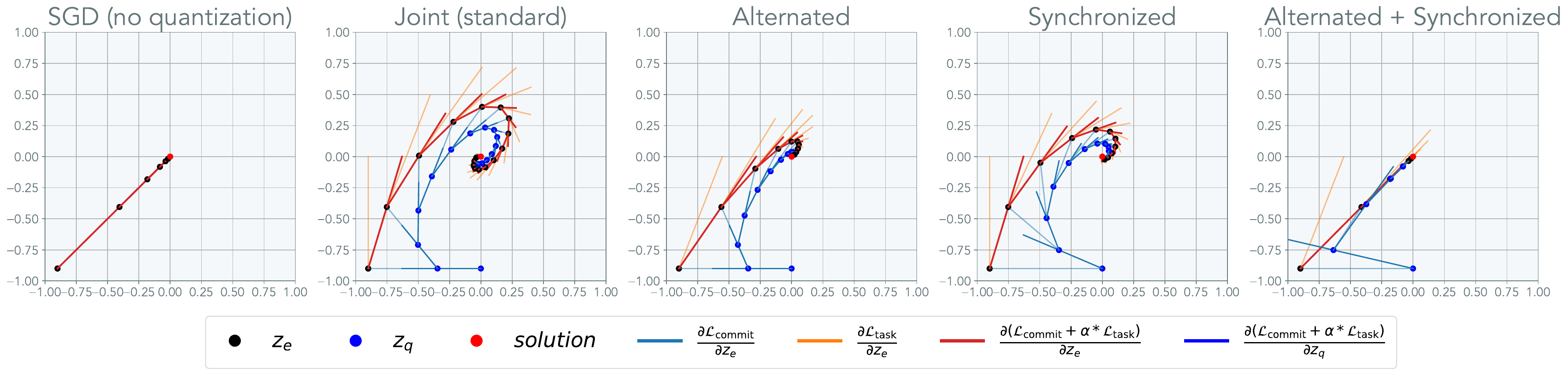
The inaccuracy of the straight-through-estimator is proportional to the error in the commitment loss -- the divergence between P and Q. In order to reduce the inaccurate estimation, we use a coordinate descent style optimization approach in which we first reduce the commitment loss before minimizing the task loss (alternated optimization).
Not only is the straight-through estimation inaccurate we find that the representation of the codebook is always delayed by a single iteration, resulting in a slowdown in convergence. We remove the delay in the codebook representation by further updating the codebook in the direction that minimizes task loss (synchronized commitment loss).
A toy example below shows how these changes affect the optimization trajectory.
Combining our proposed methods above, we get a consistent improvement in various VQ-based tasks, including generative modeling and image classification. The figure below is generated using MaskGIT* framework for CelebA. OPT refers to both alternating optimization + synchronized commitment loss. Refer to the main paper for additional results, including image classification.
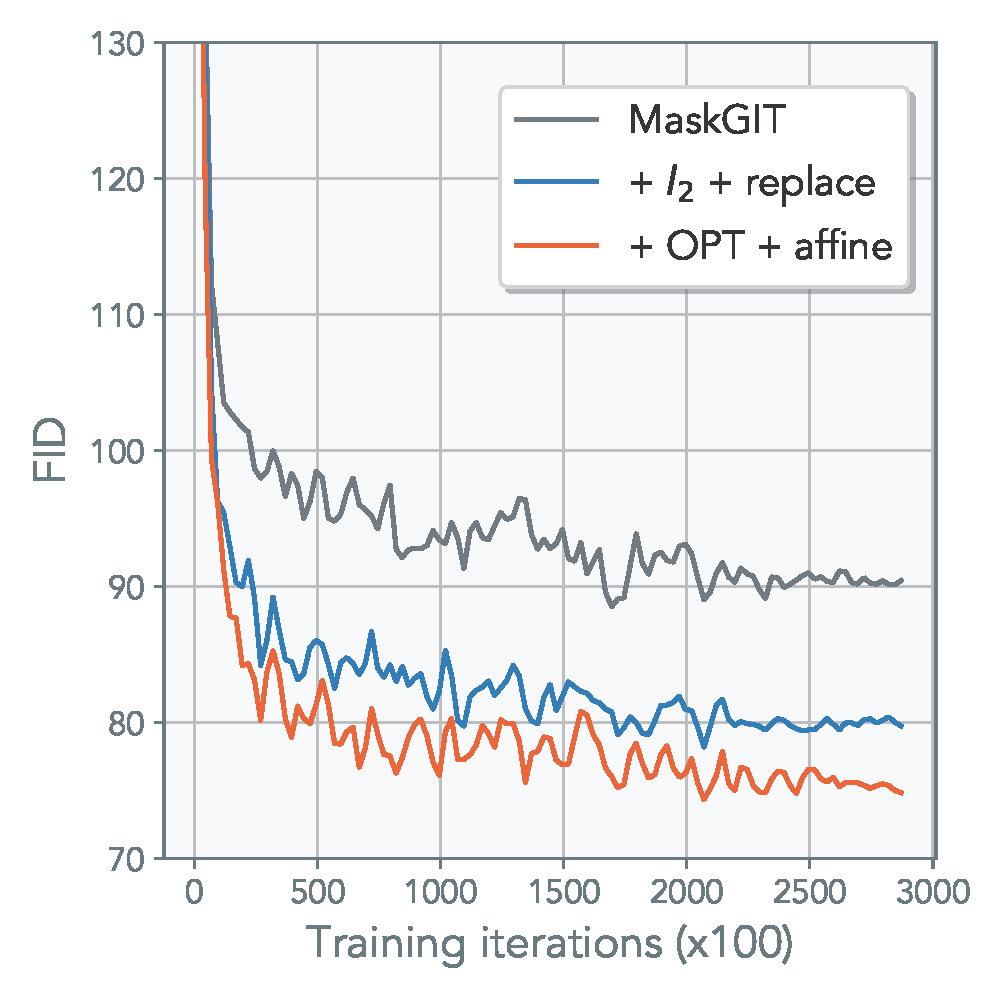
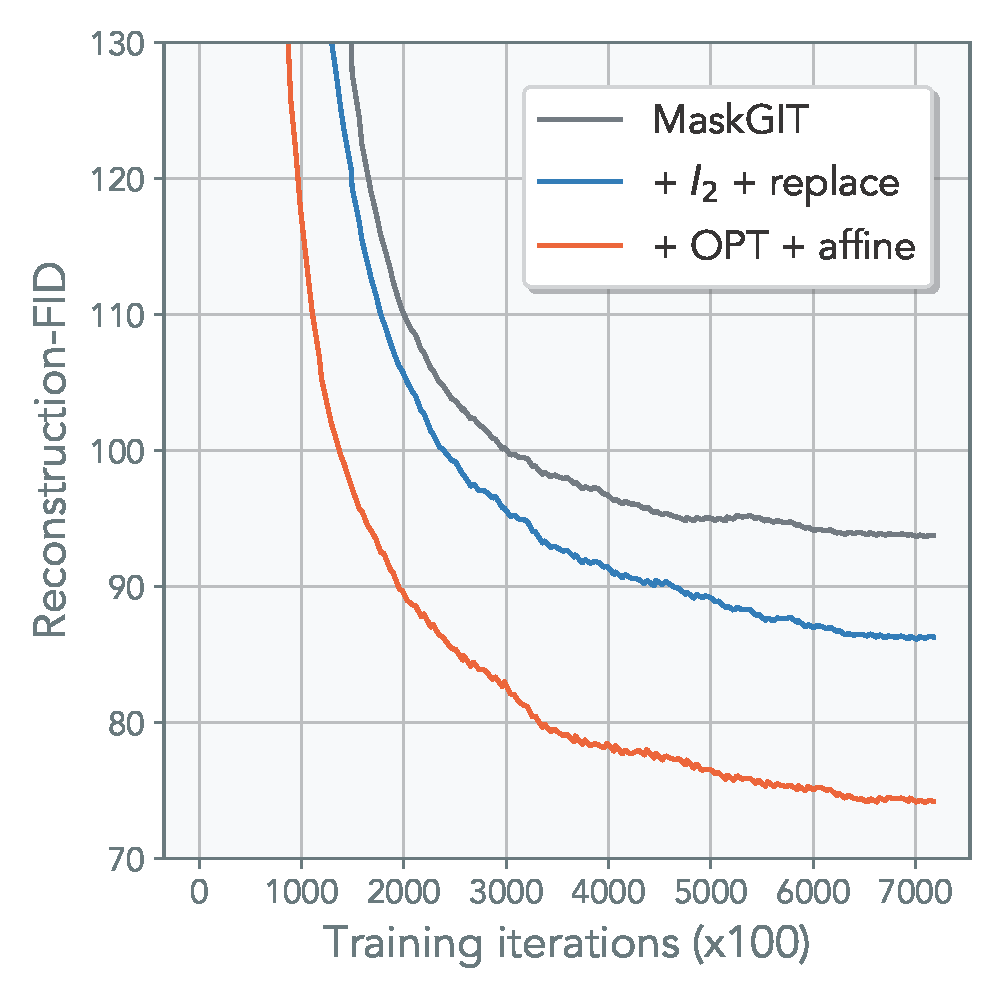
(*Note: MaskGIT was trained without perceptual and discriminative loss to reduce training and memory overhead.)
>>> git clone https://github.com/minyoungg/vqtorch
>>> cd vqtorch
>>> pip install -e .
import torch
from vqtorch.nn import VectorQuant
# create VQ layer
vq_layer = VectorQuant(
feature_size=32, # feature dimension corresponding to the vectors
num_codes=1024, # number of codebook vectors
beta=0.98, # (default: 0.95) commitment trade-off
kmeans_init=True, # (default: False) whether to use kmeans++ init
norm=None, # (default: None) normalization for input vector
cb_norm=None, # (default: None) normalization for codebook vectors
affine_lr=10.0, # (default: 0.0) lr scale for affine parameters
sync_nu=0.2, # (default: 0.0) codebook synchronization contribution
replace_freq=20, # (default: 0) frequency to replace dead codes
dim=-1 # (default: -1) dimension to be quantized
).cuda()
# when using `kmeans_init`, a warmup is recommended
with torch.no_grad():
z_e = torch.randn(1, 32, 32, 3).cuda()
vq_layer(z_e)
# standard forward pass
z_q, vq_dict = vq_layer(z_e) # equivalent to above
print(z_q.shape)
>>> (1, 64, 64, 32)
Minyoung Huh would like to thank his lab members for helpful feedbacks. Minyoung Huh was funded by ONR MURI grant N00014-22-1-2740.
Website template edited from Colorful Colorization.