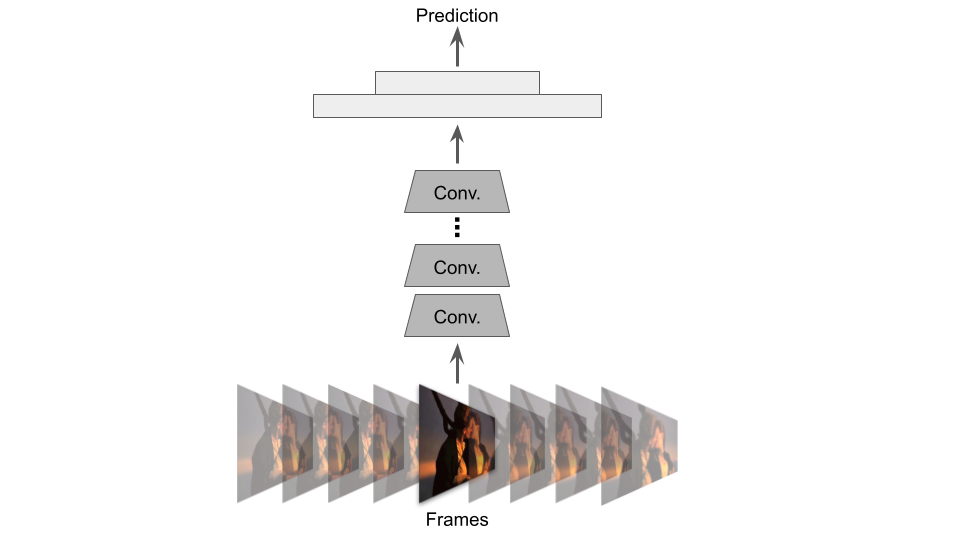
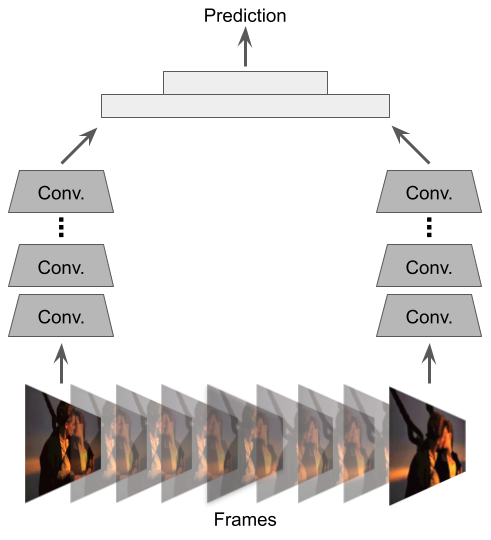
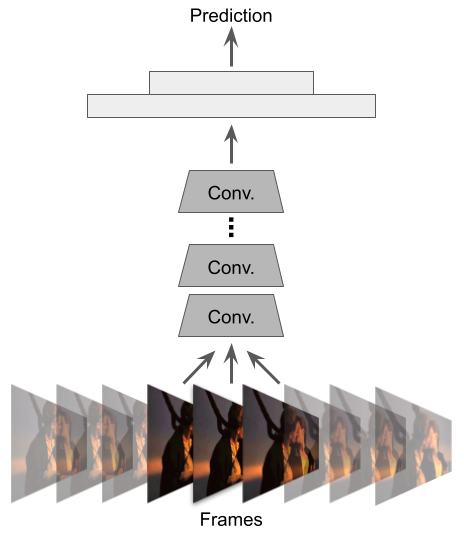
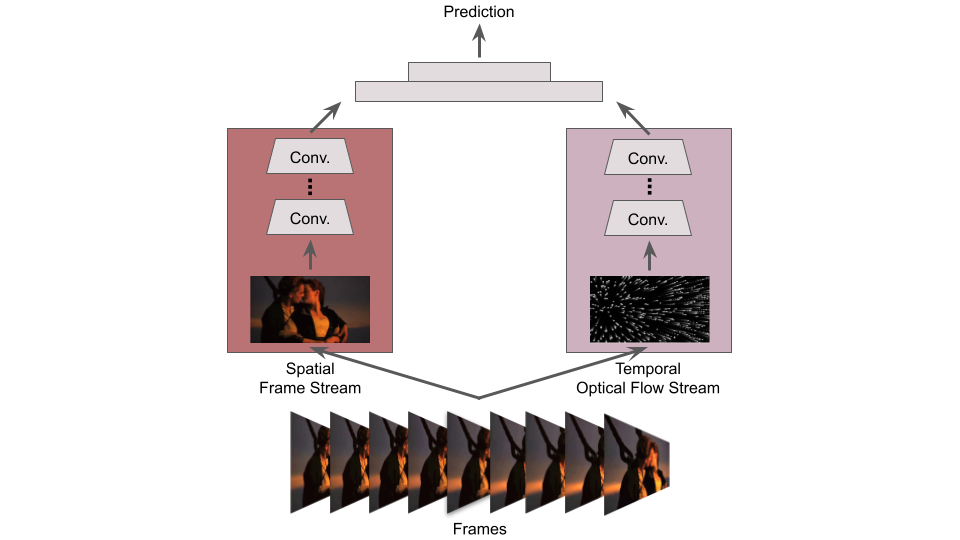
A still from Titanic (1997). Are they about to kiss, or have they already kissed? Actions can be ambiguous without temporal information.
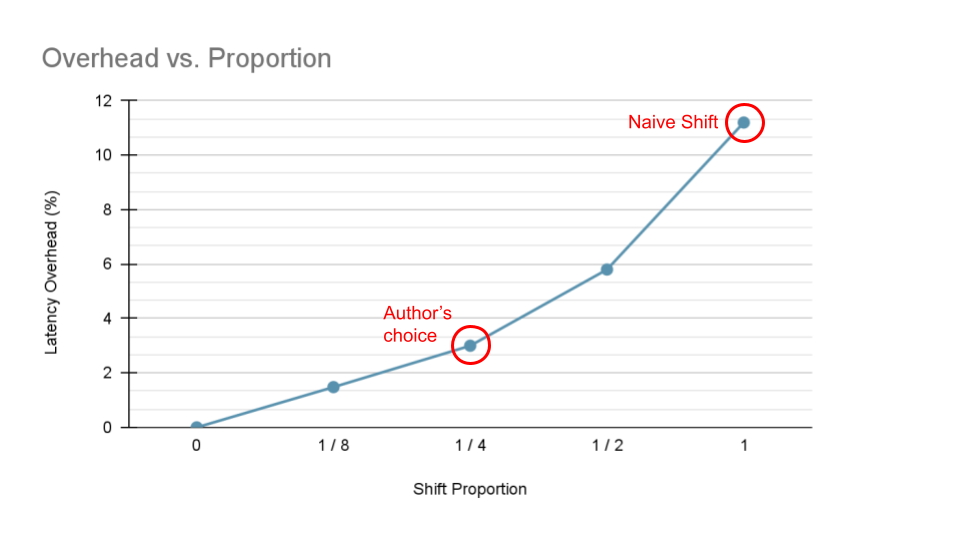
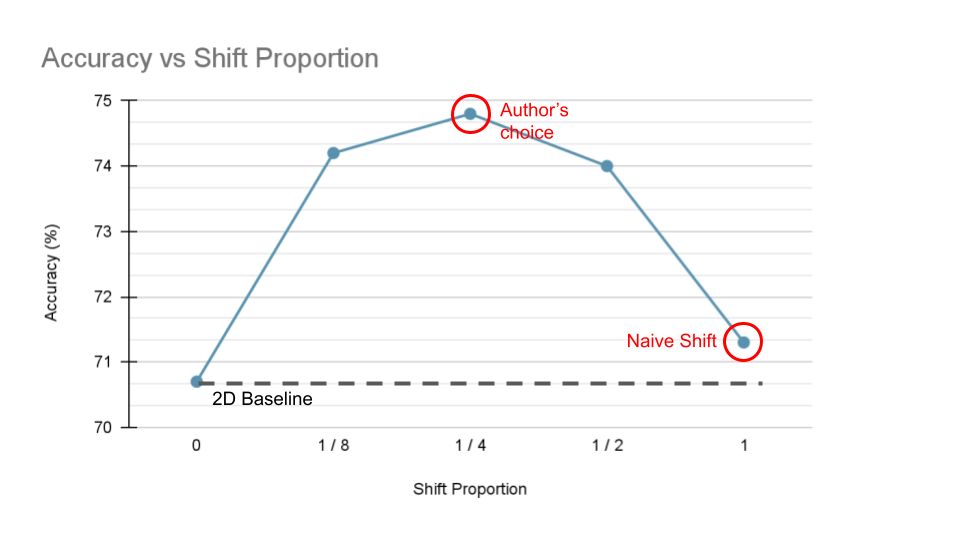
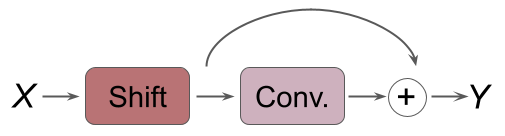
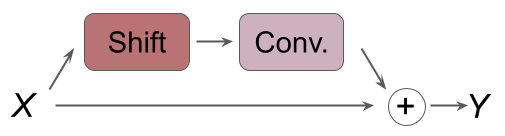
This blog will focus mainly on the paper TSM: Temporal Shift Module for Efficient Video Understanding by Lin et al. TSM shifts parts of tensors along the temporal dimension, which allows temporal information to be shared among neighboring frames. Due to the nature of the shift operations, TSM can be implemented and inserted to 2D CNNs essentially at zero computation and zero parameters. As a result, the authors argue that TSM can achieve performance of 3D CNNs while having the complexity of 2D CNNs.