Self-Supervised Audio-Visual Cross-Modal Learning
| audio-visual learning cross-modal learning self-supervised learningAs humans, we experience the world through multiple senses: sight, hearing, touch, smell, and so on. However, we don’t just use these sensory inputs independently – we combine them together in order to better understand and interpret what’s going on around us. The co-occurrence of auditory and visual signals is one particularly interesting setting to look at. There is an inherent concurrency to these modalities, resulting from the fact that sound is a kind of vibration generated by physical objects that can be visually seen. For example, if we hear a siren wailing in the distance, we might expect to see an ambulance or a fire truck pass by. Likewise, if something we hear doesn’t seem to match up with what we see – a tiny dog barking very deeply, perhaps – then we might find ourselves surprised.
The natural correspondence between audio and visual information streams promises a way for machine models to discover complex correlations within these signals, thereby learning to better understand the world. Combining parallel streams of multiple modalities for training models in this manner is referred to as cross-modal learning. Conveniently, the concurrency of audio-visual signals also provides a free and pervasive supervised signal, allowing these models to be trained using self-supervised methods, rather than having to rely on human annotators to manually curate datasets. In this way, these self-supervised cross-modal learning techniques can use videos and their matching audio to learn powerful representations of audio-visual data.
In this article, we’ll explore some of the main ideas behind cross-modal audio-visual learning. We’ll cover some general strategies for combining the two modalities and some of the methods that have been introduced in the literature over the past few years. Finally, we’ll discuss some potential improvements and research directions that can be done going forward.
Audio-Visual Representation Learning
In cross-modal learning, the main idea is to train networks for each of the different modalities being considered, which learn to embed their inputs into a shared latent space. In the self-supervised learning setting, many approaches use contrastive learning methods, which learn representations by minimizing the distance in latent space between positive pairs of samples and maximizing the distance between negative pairs of samples. Intuitively, this means that inputs from each modality corresponding to the same semantic object should be placed close to each other in the latent space, while those that correspond to different objects should be far apart. For example, given a video of a dog barking, the visual embedding for the dog should be close to the audio embedding of the bark, but far from the audio embedding for a different sound, such as a meow.
Recent studies on learning audio-visual representations can generally be categorized into two types: Audio-Visual Correspondence (AVC) and Audio-Visual Synchronization (AVS). Both of these settings use a verification task that involves predicting whether an input pair of an audio clip and a video clip match or not. Here, positive input pairs are typically sampled from the same segments in a given video, under the assumption that the video and audio streams are well-matched up and correspond to one another.
The main difference between AVC and AVS is in how negative audio and video pairs are chosen. In AVC, negative pairs are mostly constructed by sampling audio and video frames from different videos, while in AVS, negative pairs are sampled from different parts of the same video. We can think of AVC as a task where a model learns to match visual objects with specific sounds, while AVS is a task where a model learns to locate the most relevant piece of audio that matches a video segment.
In either case, the representations learned from these strategies can be applied towards downstream tasks that use both audio and visual information. These include (but obviously are not limited to):
- Audio-to-video synchronization (detecting and fixing misalignments)
- Speaker localization and tracking
- Multi-speaker sound source separation
- Active speaker detection
- Audio-visual biometric matching
Depending on how the models are trained, these cross-modal embeddings can also be useful for uni-modal tasks as well, such as audio-only speaker verification and video-only visual speech recognition (lip reading).
Combining Acoustic and Visual Information
So, how do we actually go about combining audio and video to learn meaningful representations? At a high-level, it’s fairly simple. As mentioned previously, the idea is to train a two-stream model (one stream for each modality), which projects the audio and video inputs onto a shared latent space. By applying a contrastive loss to these embeddings, the overall model learns to encode each modality in a semantically meaningful way.
Things become more interesting when we start to consider how exactly to implement the contrastive loss. Early methods for learning cross-modal embeddings, such as SyncNet [1] and AVE-Net [2], were trained using pairwise correspondence criteria. That is, they looked at individual audio-video pairs in order to compute the contrastive loss, with the goal of minimizing or maximizing the Euclidean distance between positive or negative pairs, respectively. This is analogous to the method used to train Siamese networks.
But wait – couldn’t we use a more general, multi-way contrastive loss instead? After all, it’s been shown in supervised metric learning that having multiple negatives can be helpful compared to pairwise training objectives.
This is exactly what Chung et al. [3] did, posing the training criterion as a multi-way matching task between audio segments and and one video segment. In their work, they sample audio segments from the same video, where only one of them corresponds to the video segment in time. By computing the pairwise similarities between the negative pairs and one positive pair, the network is trained with a cross-entropy loss on the inverse of these distances after passing them through a softmax layer.
Intuitively, this causes the similarity between matching pairs to be greater than those of non-matching pairs. The training objective also naturally lends itself to AVS, where the task is to find the most relevant sample in one domain to a query in another modality.
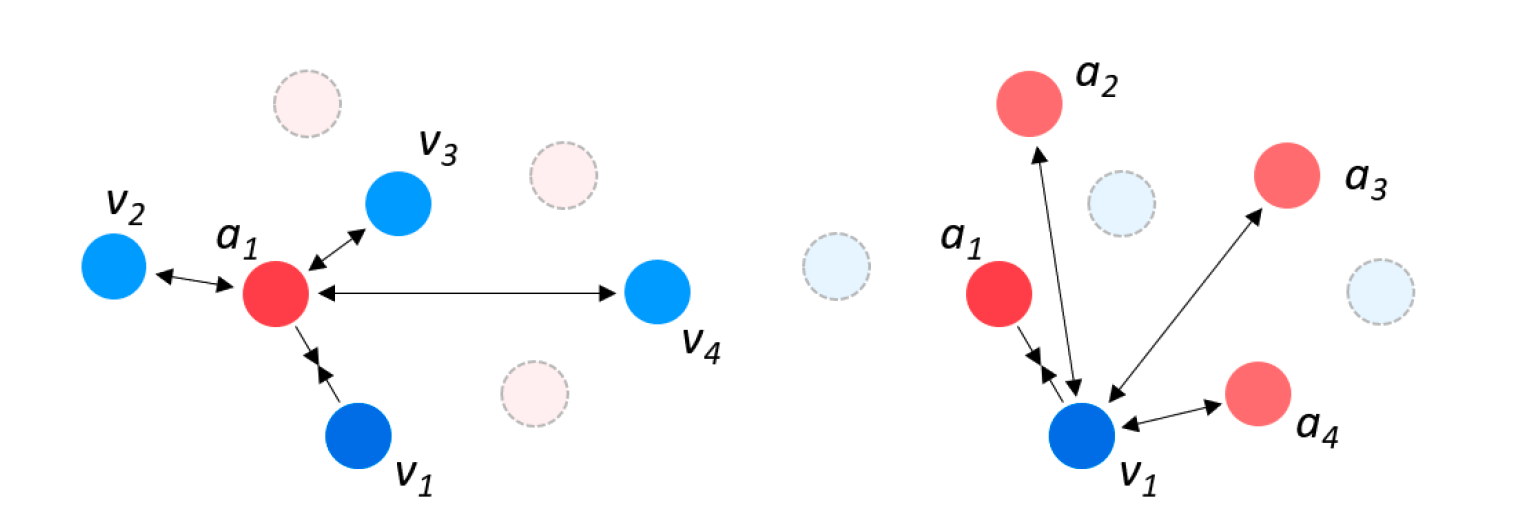
The embeddings learned through this training method turn out to work pretty well for audio-to-video synchronization and visual speech recognition. But there’s a catch — while the method enforces intra-class separation and inter-class compactness across modalities, it doesn’t penalize or optimize metrics within modalities. That is, it doesn’t explicitly enforce different inputs from the same modality to be far apart.
To address this issue, the authors released a follow-up work [4], in which they incorporated additional training criteria that would enforce intra-class feature separation within each of the audio and video modalities. More specifically, they added contrastive losses for audio-audio and video-video samples, where sample pairs within the same modality were assigned to be negative. Since it isn’t possible to obtain positive pairs from the same class in an unsupervised setting, they chose positive pairs using the corresponding embedding from the other modality, since the features for both modalities are represented in the same latent space.
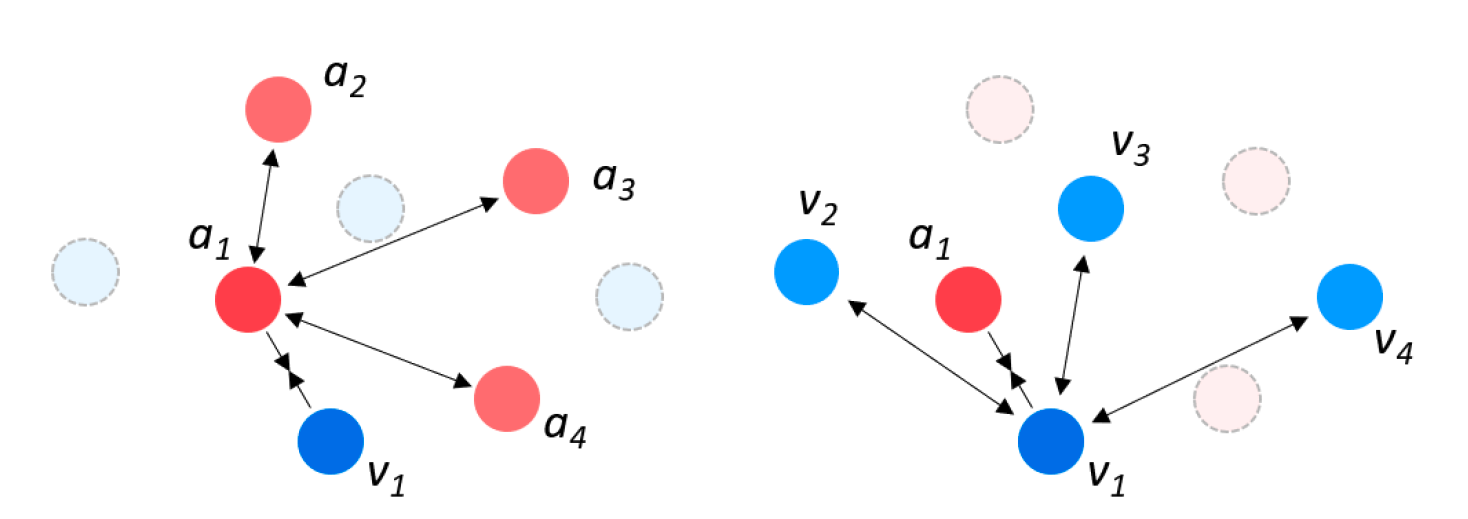
This contribution is particularly important within the self-supervised representation learning paradigm, as it makes the learned representations from the model more conducive for uni-modal downstream tasks in addition to cross-modal tasks.
Beyond Joint Latent Spaces: From Unlabeled Video to Audio-Visual Objects
Cross-modal audio-visual embeddings derived from the above methods are useful and interesting, but you would be forgiven for wondering how much they actually contribute to a machine’s understanding of the world. For humans, a more natural way of looking at the world is to organize visual cues into objects. In the context of combining vision with audio, we group different objects together not only because they look alike or move similarly, but also because grouping them in this way helps us explain the causes of co-occurring audio signals.
Given this, we can imagine a task where we would like to ingest the audio and visual streams of a video and transform them into a set of discrete audio-visual objects. This is a difficult problem for several reasons:
- There may potentially be multiple visually similar sound-generating objects in a given scene, and the model must be able to correctly attribute a sound to its actual source.
- Objects in a video may move over time.
- There can be other objects in the video that do not contribute sound, but provide distractions in the scene.
Afouras et al. [5] aim to address these challenges, proposing a network that builds on other works on self-supervised audio-visual localization. Their model, the Look Who’s Talking Network (LWTNet), is able to use synchronization cues to detect sound sources, group them into distinct instances, and track them over time as they move. Here, each audio-visual object is represented as the trajectory of a potential sound source through space and time.
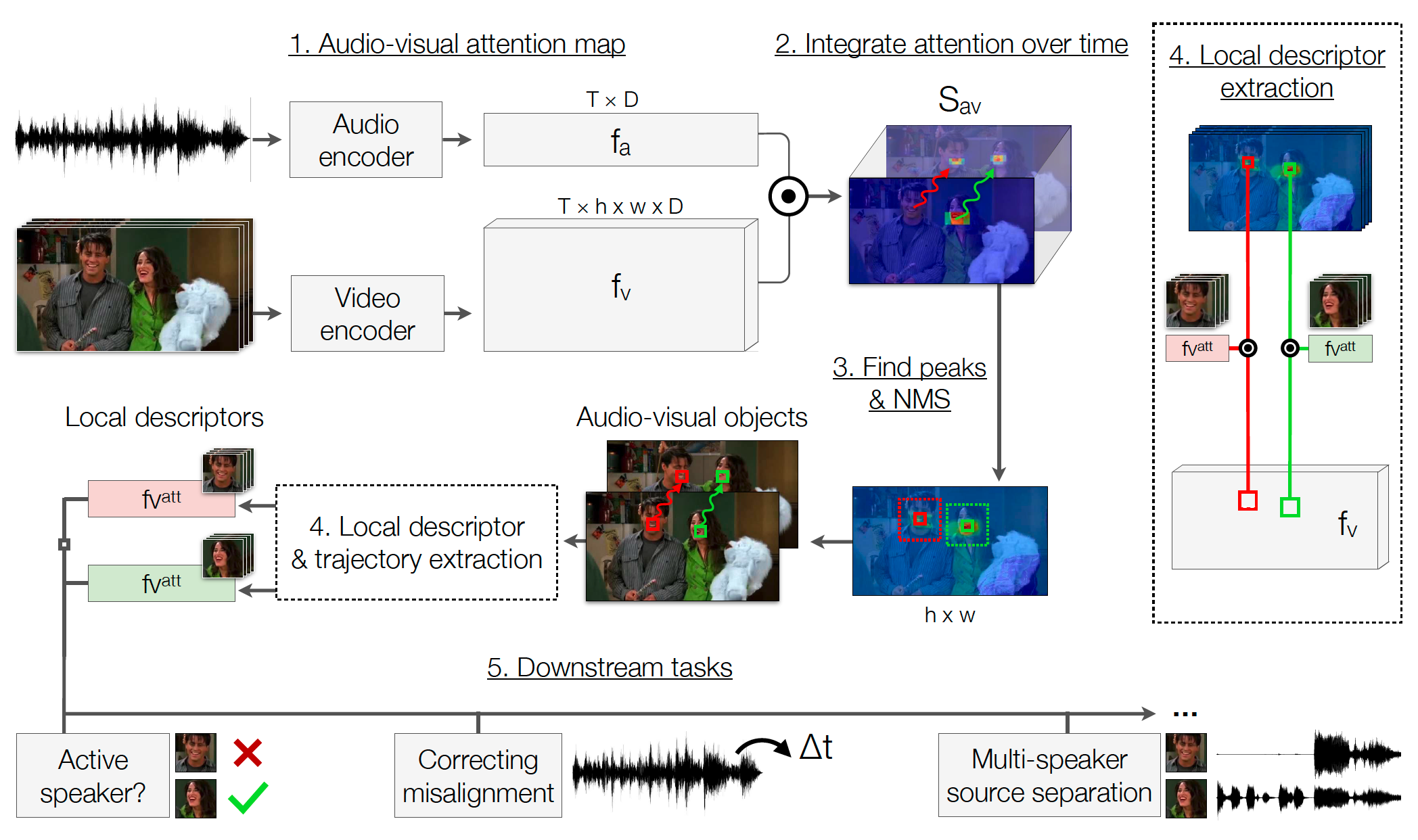
LWTNet uses a bottom-up grouping procedure to propose discrete audio-visual objects from raw video. It first estimates per-pixel and per-frame synchronization evidence from the two modality streams. This is done by computing a per-pixel attention map that picks out regions of video whose motions have a high degree of synchronization with the audio. The attention mechanism is aimed at providing highly localized spatio-temporal information. The model then outputs embeddings for each audio clip and for each pixel, such that if a pixel’s vector has a high dot product with that of the audio, then it is likely to belong to that sound source.
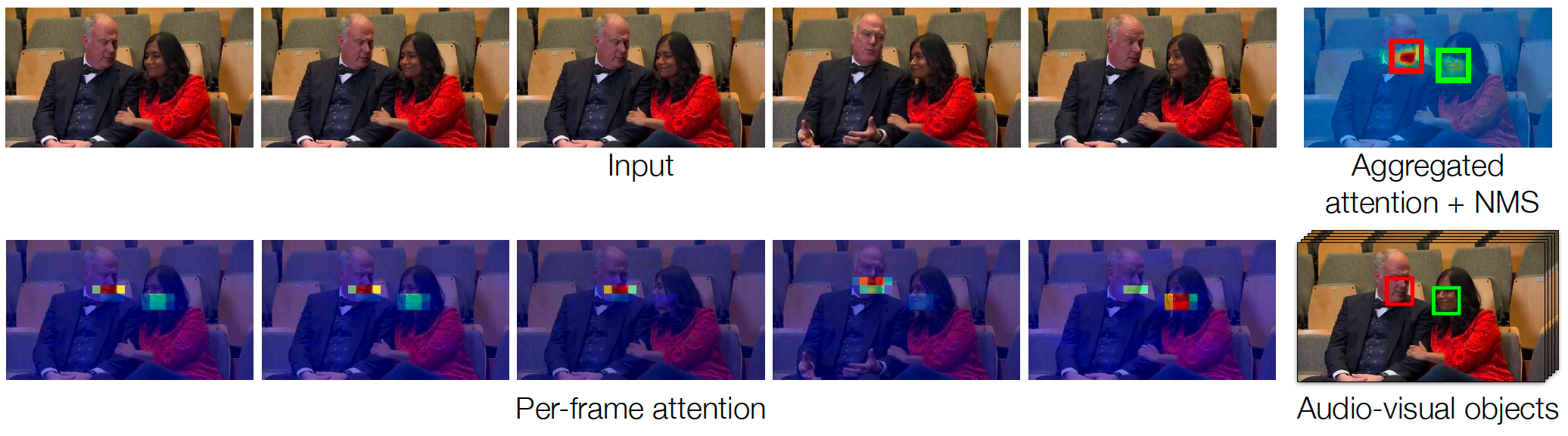
LWTNet aggregates these audio-visual attention maps over time via optical flow. This allows it to deal with moving objects in a video. Then, the model extracts discrete objects by detecting spatial local maxima (peaks) in the temporally aggregated synchronization attention maps; after applying non-maximum suppression (NMS), the remaining peaks are determined to be distinct audio-visual objects. From these objects, the model locates the position of the sound source in the video frame and selects the corresponding spatial embedding from the visual feature map. These embeddings are then available to be used in downstream tasks.
The authors apply LWTNet to the setting of tracking human speakers (“talking heads”) in video, and test the usefulness of the audio-visual object representations on several downstream tasks.
Talking head detection and tracking
LWTNet can be used for spatially localizing speakers in a video. To do this, the model uses the tracked location of an audio-visual object in each frame.
![]()
Active speaker detection
LWTNet can also locate potential speakers and decide whether or not they are speaking. This can be viewed as deciding whether an audio-visual object has strong evidence of synchronization with a given frame. The correlation score is then thresholded to make a binary decision as to whether an object corresponds to an active speaker or not.
Encouragingly, LWTNet demonstrates the ability to generalize to non-human speakers. When applied to videos from The Simpsons and Sesame Street, it succeeds in detecting active speakers even when multiple heads are present in the video frame and significantly outperforms baseline models that use face detection systems.


Multi-speaker source separation
The audio-visual object representations from LWTNet can also be used for separating the voices of multiple speakers in a video. Given a video with multiple people speaking concurrently on-screen (e.g. a television debate show), the task is to isolate the sound of each speaker’s voice from the overall audio stream. This is done using an additional network that isolates speakers’ voices given a waveform containing an audio mixture and an audio-visual object.
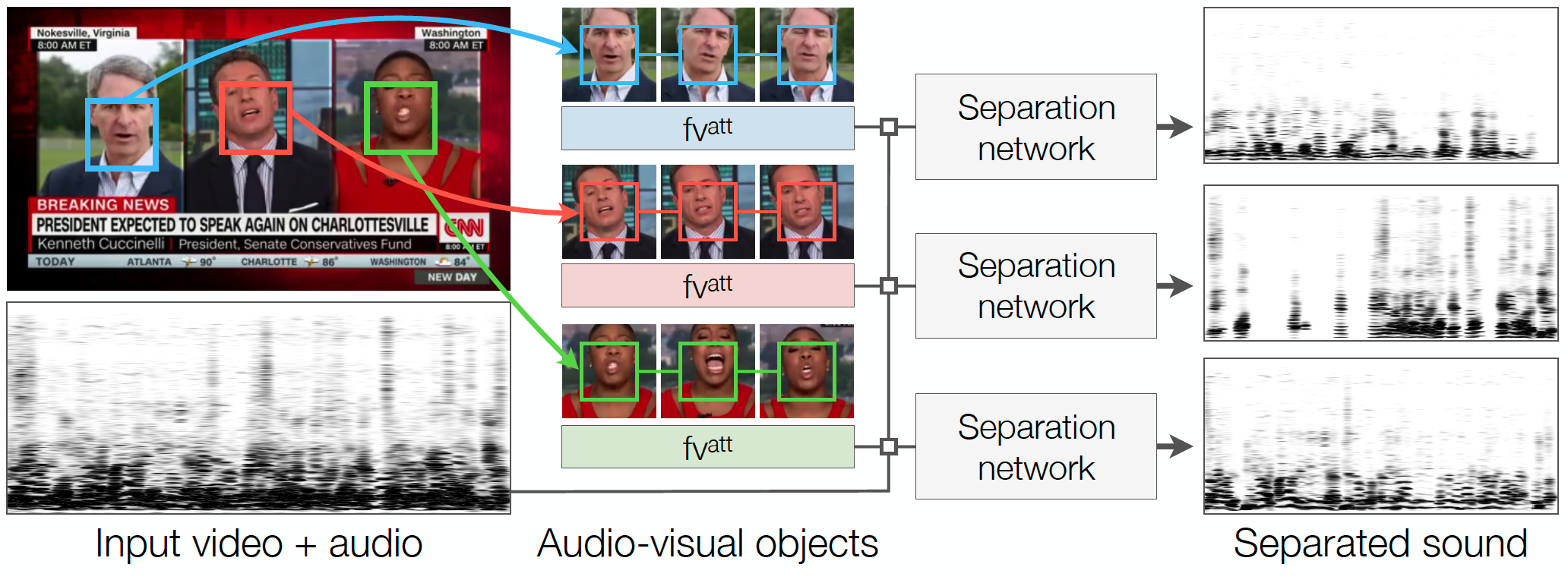
Correcting audio-visual misalignment
Finally, the authors demonstrate LWTNet’s ability to correct misaligned audio-visual data — a problem that often occurs in the recording and television broadcast setting. Given a video with unsynchronized audio and visual tracks, this is done by shifting the audio to find the temporal offset that maximizes the audio-visual attention weight for the frame (which can be computed by taking the dot products between the audio and video embeddings from the network).
Summary
The works described in this article mostly addressed the specific task of aligning audio of human speech with videos of talking faces. However, there are many more interesting opportunities to extend audio-visual learning towards other domains, such as the analysis of music or ambient sounds. Indeed, some recent work has addressed the problem of learning representations for more general downstream tasks such as action recognition and environmental sound classification [6]. In addition, there are opportunities to develop training methods that are more robust to noisy data, such as when audio does not offer useful information about the contents of a video and vice versa; one such recent example is [7].
In general, audio-visual cross-modal learning promises many advantages over uni-modal learning tasks, as the combination of multiple data streams means that machine learning models are able to learn from much richer sources of information. Its propensity towards self-supervision also means that it can take advantage of large amounts of raw data without the need for human annotators to manually review videos and label objects of interest. This line of research offers potential for agents to learn a more meaningful understanding of the world, and it is most definitely a fruitful topic for future work and exploration.
References
[1] J. S. Chung and A. Zisserman, “Lip Reading in Profile,” in British Machine Vision Conference, 2017.
[2] R. Arandjelovic and A. Zisserman, “Objects that Sound,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 435–451, 2018.
[3] S.-W. Chung, J. S. Chung, and H.-G. Kang, “Perfect match: Improved Cross-Modal Embeddings for Audio-Visual Synchronisation,” in 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3965–3969, IEEE, 2019.
[4] S.-W. Chung, H.-G. Kang, and J. S. Chung, “Seeing voices and hearing voices: Learning discriminative embeddings using cross-modal self-supervision,” Interspeech, 2020.
[5] T. Afouras, A. Owens, J. S. Chung, and A. Zisserman, “Self-Supervised Learning of Audio-Visual Objects from Video,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 208–224, Springer, 2020.
[6] P. Morgado, N. Vasconcelos, and I. Misra, “Audio-Visual Instance Discrimination with Cross-Modal Agreement,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12475–12486, 2021.
[7] P. Morgado, I. Misra, and N. Vasconcelos, “Robust Audio-Visual Instance Discrimination,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12934–12945, 2021.