|
|
|
|
|
|
|
|
|
|
|
|
GitHub |
arXiv |
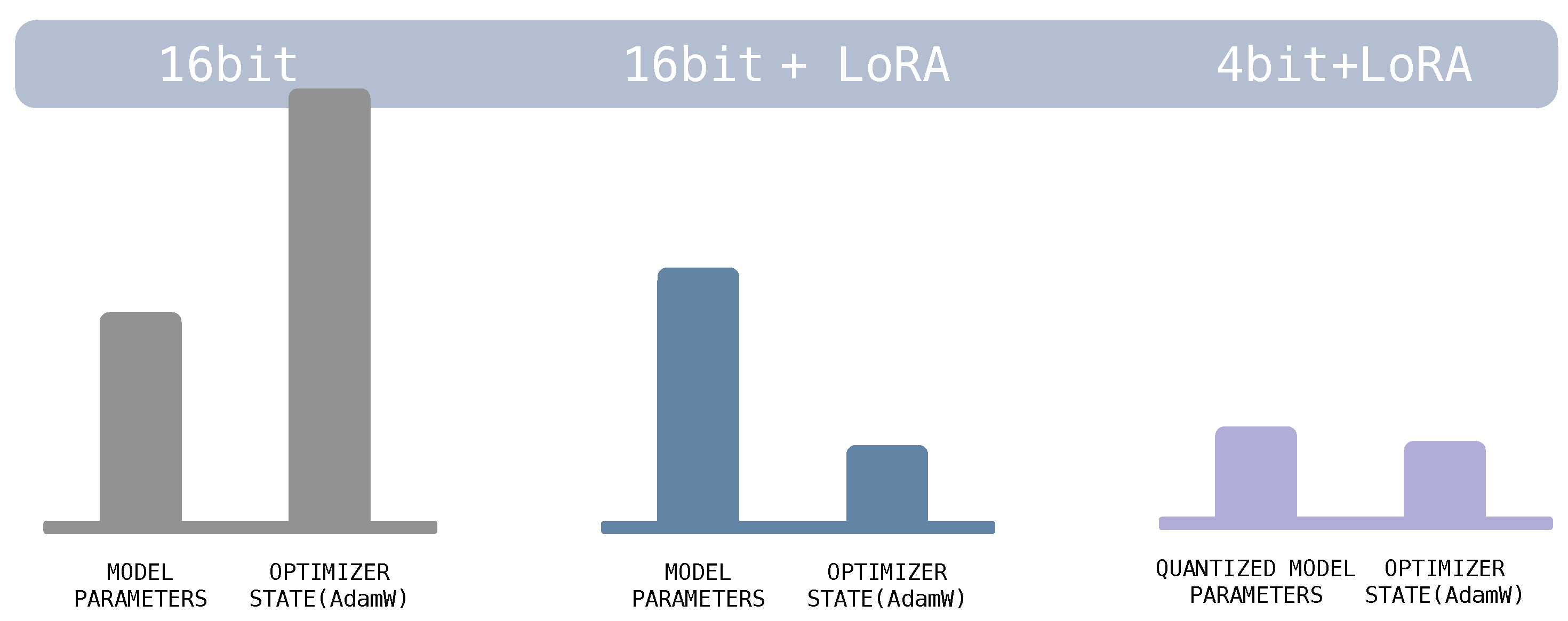
Tremendous efforts have been made to enable large-scale model fine-tuning on memory-limited hardware devices using quantization and adapters. Methods such as QLoRA have demonstrated the feasibility of fine-tuning a 7B LLM with just 6GB of GPU memory.
But what about model pre-training? Can we leverage the memory-efficient algorithms when training from scratch?
We demonstrate that it is possible to train with LoRA alone to match standard pre-training performance. This enables training of much larger models using computing devices with fraction of the memory and communication cost.
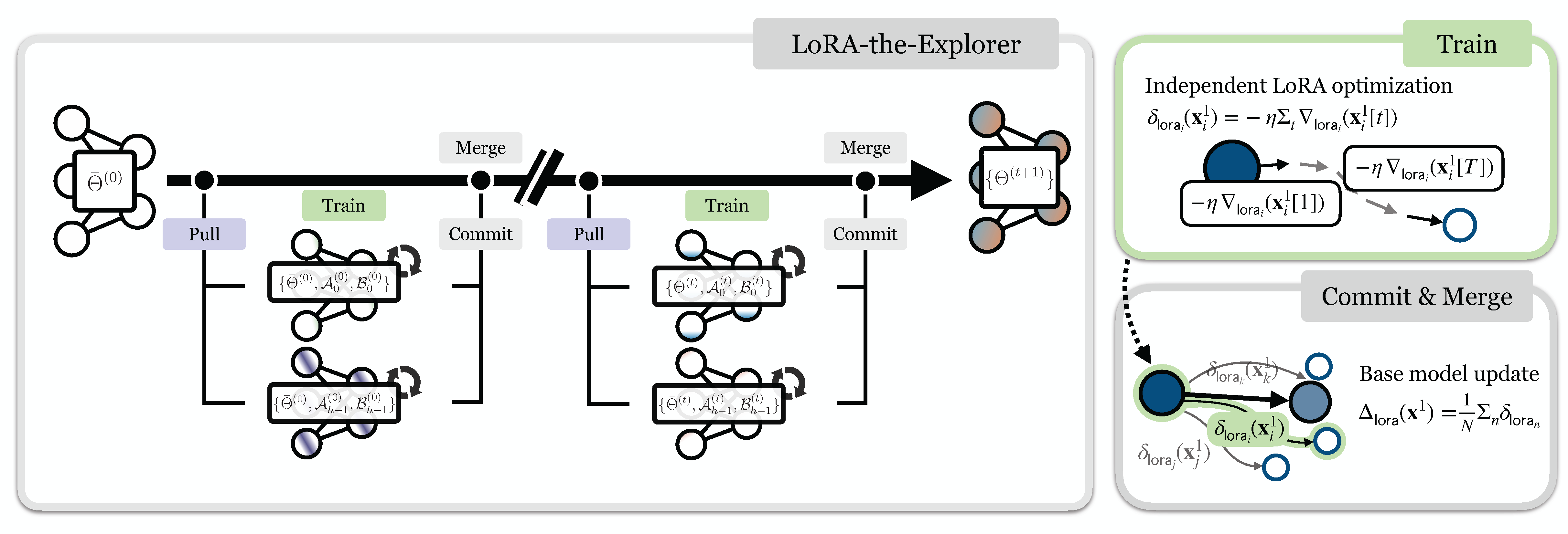
Our method, LoRA-the-Explorer (LTE), involves the following steps:
This approach ensures that the LoRA parameters serve as individual "gradient" updates for the main set of weights. By doing so, it enables collaborative training of the model using LoRA adapters ... similar to an open source GitHub project :)
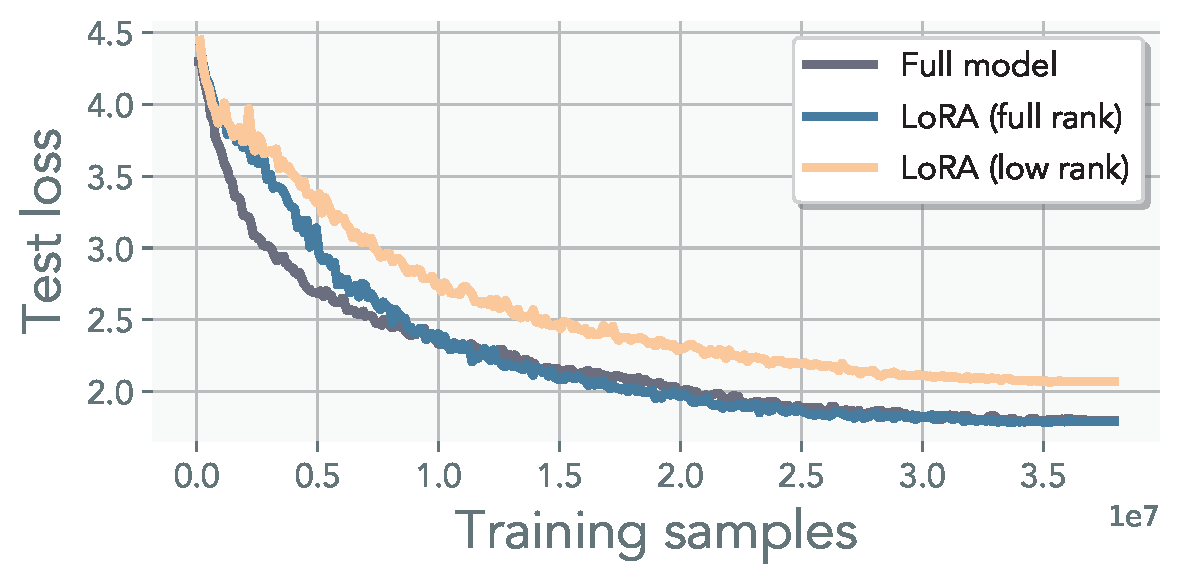
Observation 1: Models trained with LoRA alone cannot fully recover pre-training performance. However, increasing the rank r or employing a multi-head representation enables these models to achieve the desired performance levels.
Observation 2: We empirically observe the effective rank of the gradients increases over time, which signals the inability to match performance with a single LoRA alone.
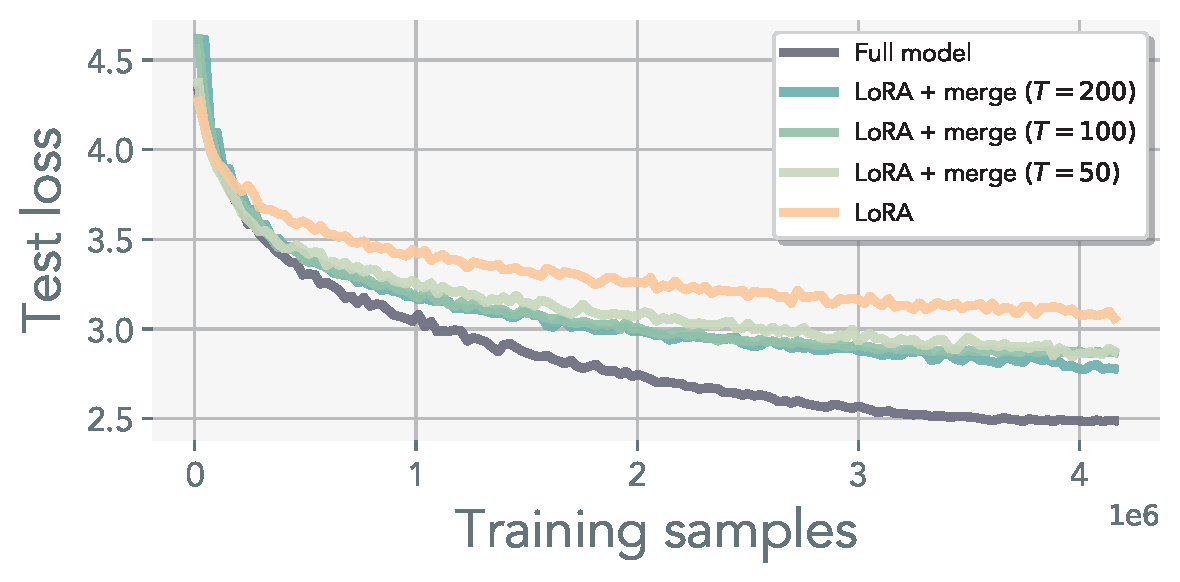
Observation 3: Sequential merging, while a viable approach to recover the full-rank weight representation, is unable to recover the full-model pre-training performance in practice. Suggesting the need for full-rank update iterates.
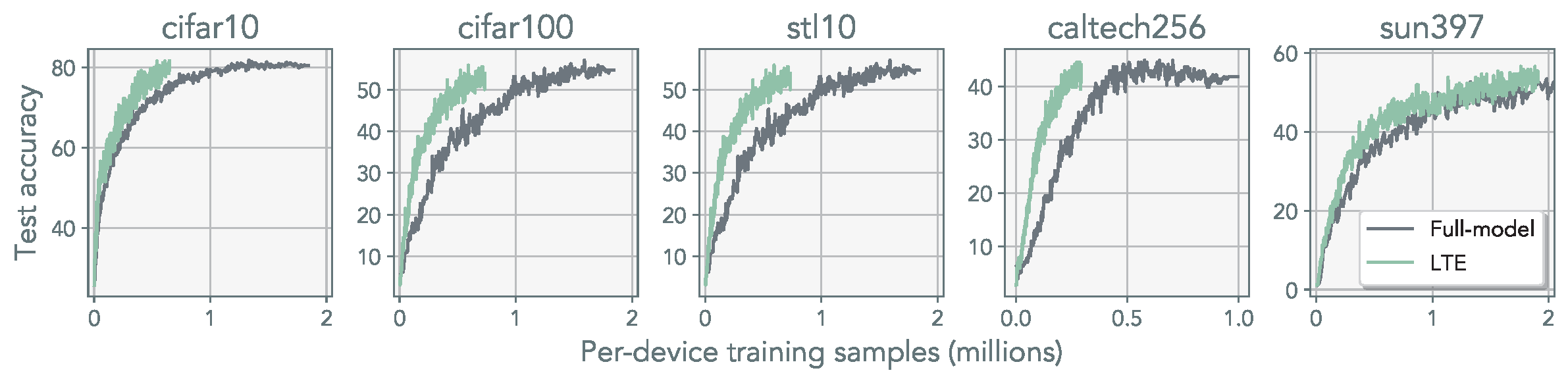
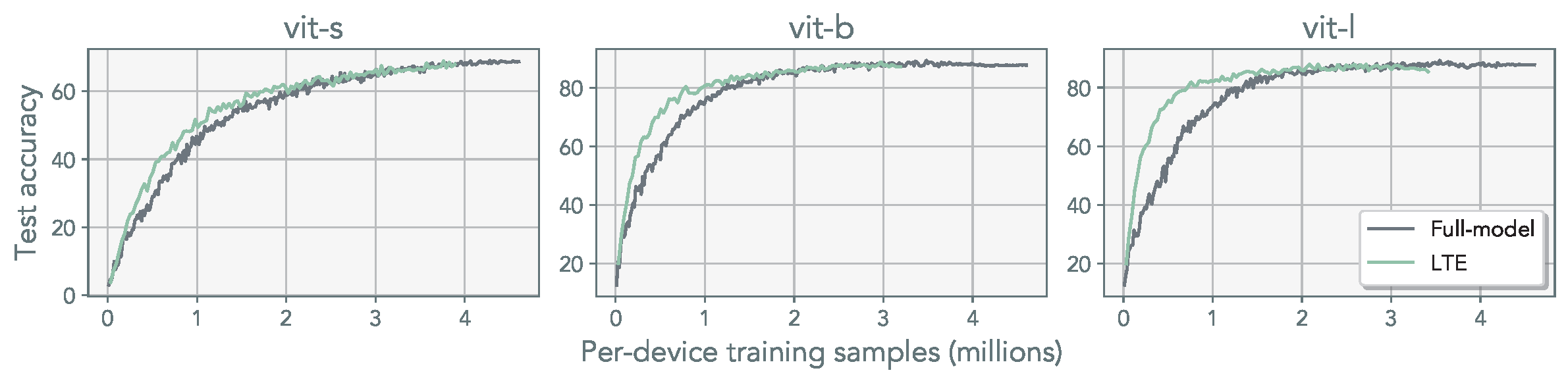
Observation 4: We demonstrate that parallel LoRA merging can precisely replicate the full-rank weight update. Furthermore, we show that even with infrequent synchronization, our method remains effective for pre-training.
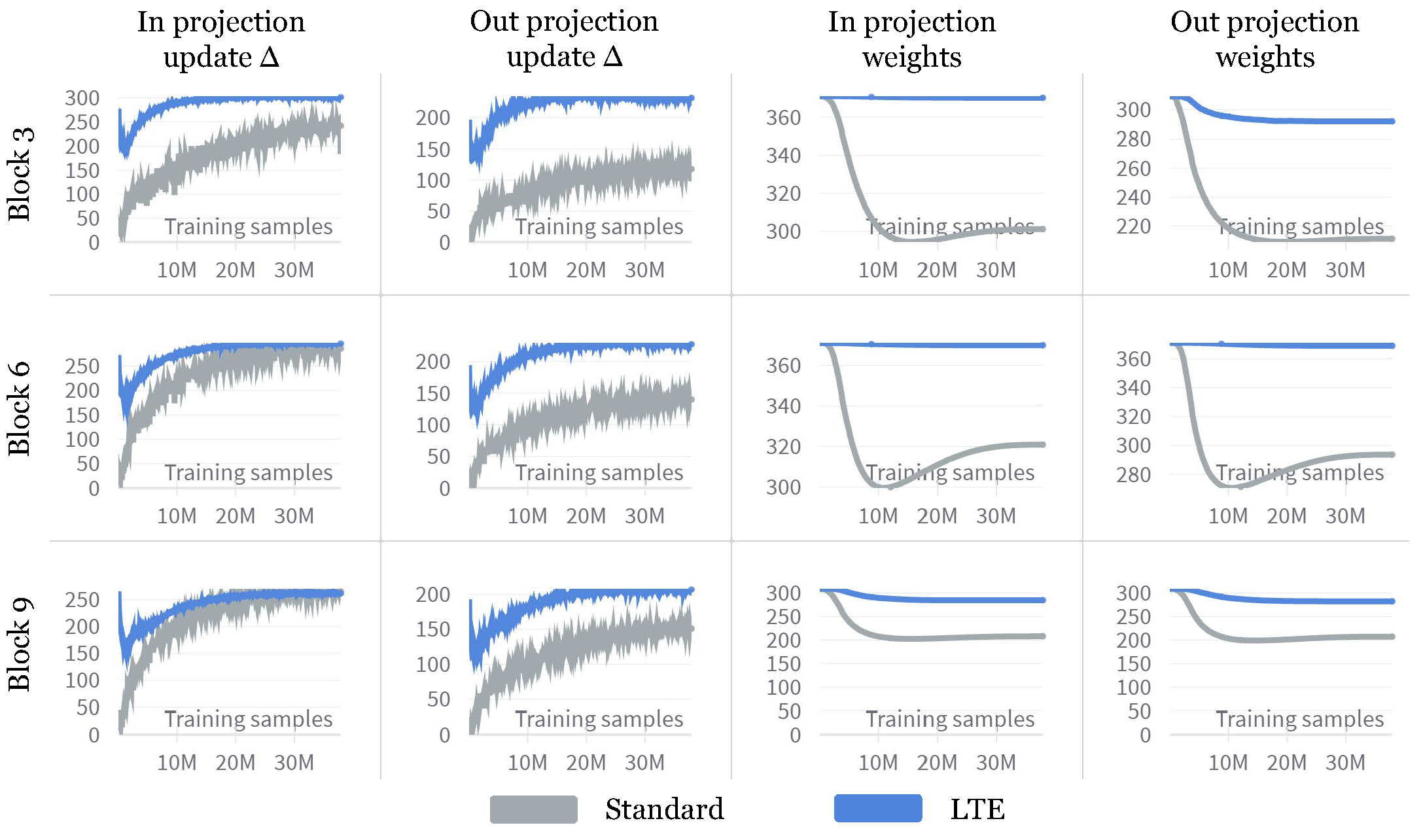
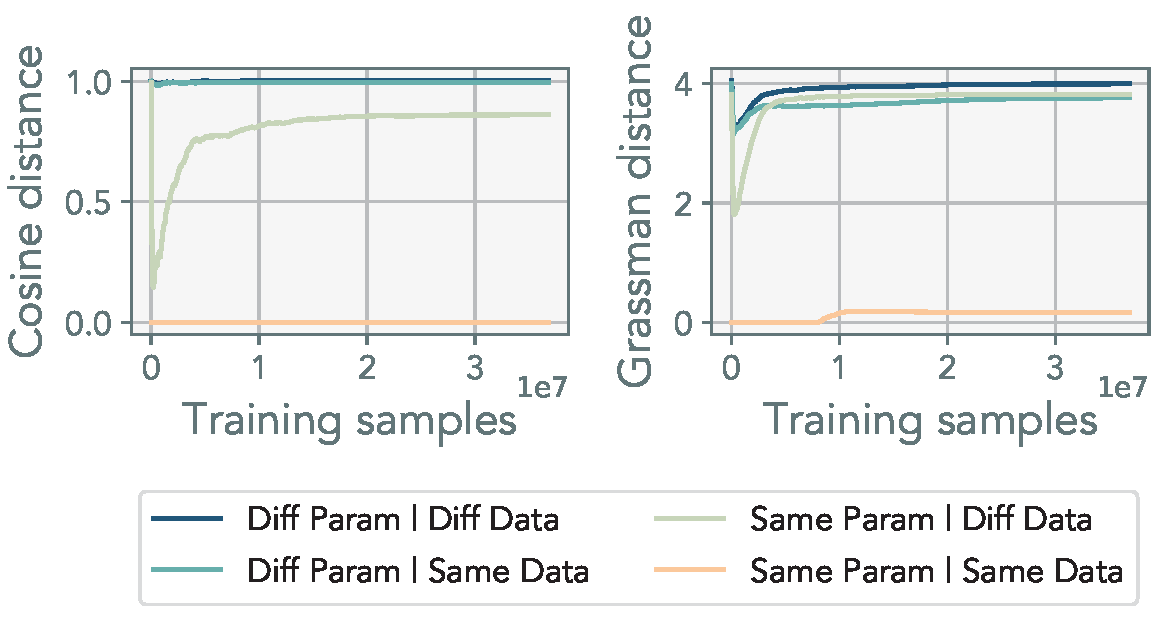
Observation 5: Even when trained in parallel, LoRA heads maintain orthogonality throughout the training process.
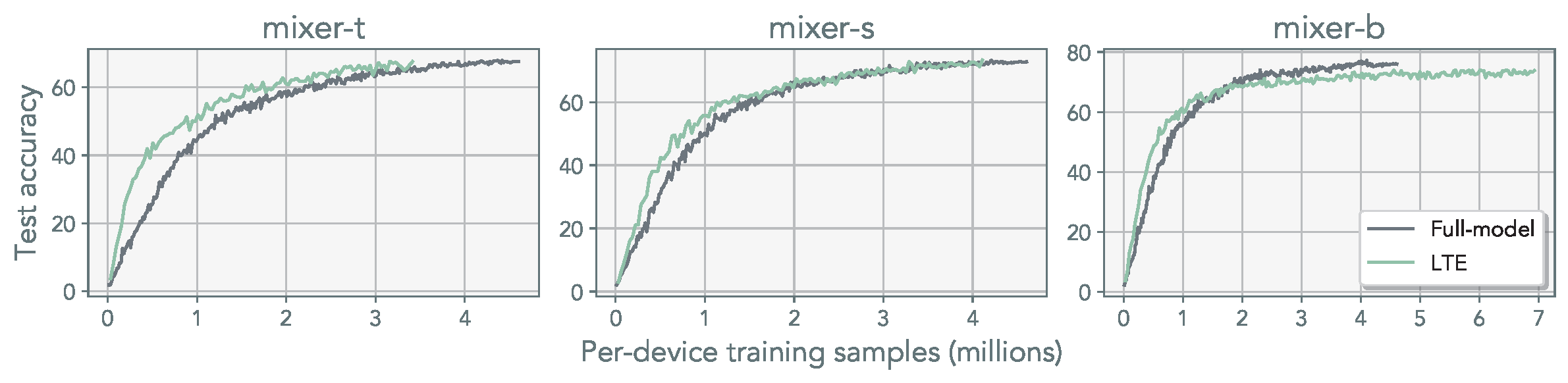
Our results suggest LTE is a competitive parameter-efficient framework for distributed training. We highlight several directions for further exploration:
Our initial findings validate the potential of low-rank adapters in neural network training, marking a significant step forward. However, further testing on larger models is essential to test the scalability of our approach. We believe our method opens up and contributes to many avenues:
Through addressing these open questions, we hope to envision a collaborative ecosystem embodying the concept of the "wisdom of the crowd."
@article{huh2024lte,
title={Training Neural Networks from Scratch with Parallel Low-Rank Adapters},
author={Huh, Minyoung and Cheung, Brian and Bernstein, Jeremy
and Isola, Phillip and Agrawal, Pulkit},
journal={arXiv preprint arXiv:2402.16828},
year={2024}
}
The research was sponsored by the Army Research Office and was accomplished under Grant Number W911NF-23-1-0277. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. MH was supported by the ONR MURI grant N00014-22-1-2740 and the MIT-IBM Watson AI Lab. JB was funded by the MIT-IBM Watson AI Lab and the Packard Fellowship. PI was funded by the Packard Fellowship. BC was funded by the NSF STC award CCF-1231216. We thank Han Guo, Lucy Chai, Wei-Chiu Ma, Eunice Lee, Dave Epstein, and Yen-Chen Lin for their feedback and emotional support on the project.